
Generative Artificial Intelligence (GenAI) has emerged as a transformative technology with the potential to revolutionize various industries. GenAI offers a powerful tool for streamlining processes, driving efficiency, and achieving scalability. Organizations can automate mundane tasks, improve decision-making, and enhance overall operational performance using GenAI.
GenAI has applicability across industries including Healthcare, Manufacturing, Insurance, Banking, Legal, and within Enterprise for all departments like IT, Finance, HR, Sales, and Operations. GenAI works best for use cases where content needs to be generated.
We usually use RAG pipelines to ingest historical documents and then generate new sections of text for specific use cases. In general, we implement solutions that generate a specific list of text sections or chunks. Any changes to the list of sections/chunks will require changes to code and testing.
In comes the metadata-driven approach that can be used to generate sections/chunks in a configurable manner with the addition of section definition and dependencies on other chunks with minimal code changes.
We first define chunk definition that includes its metadata including name, vector index, category, chunk dependency, and version among others. We can define as many chunk definitions as required even across departments and use cases. It is also possible to have different kinds of chunks in the Organization, some can be generic across enterprise while others will be specific to use cases or departments.
Once the solution is implemented and the request is received with a list of chunks to be generated, it first creates a Dynamic Chunk map where it arranges chunks into multiple levels based on dependencies. Once Dynamic Chunk map is ready it starts generating Level 1 chunks in parallel. After Level 1 Chunks is generated, second level chunks generation is initiated. It can go onto any level of chunk dependency, and we have tested up to 5-6 levels of chunks.
Once all the chunks are generated those can be used to populate template documents for target use cases like RFP responses and legal contracts among others. The same solution can be used to extend to new use cases by ingesting historical documents and defining Chunk definitions and dependencies.
System prompts used in the solution are externalized and prompts for new chunks will be defined in YAML files and will be part of Chunk definitions.
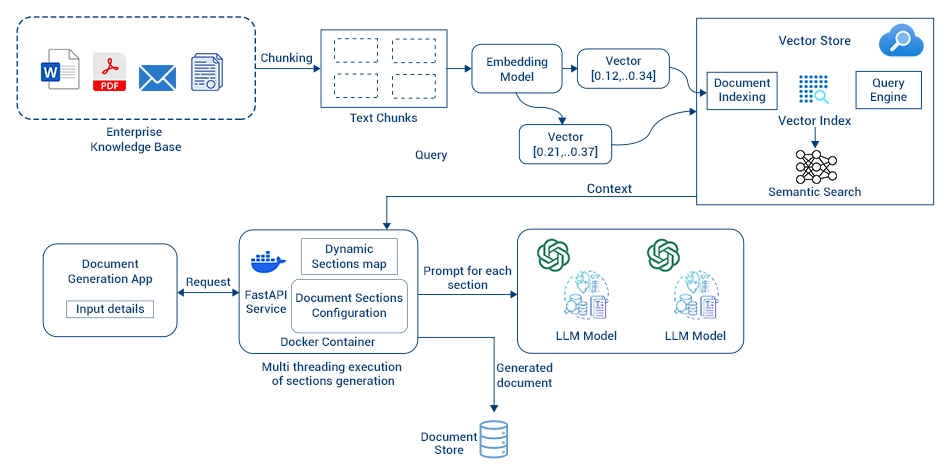
Flow includes ingestion of historical documents/data from the Enterprise Knowledge base, chunking and storing into multiple Vector databases based on configuration.
The user will input details from the Document Generation App that will send requests to the backend service generate a dynamic list of chunks and populate the target document template.

 +91 253 6630710
+91 253 6630710 781.258.1274
781.258.1274 +44 (0) 7446 87 37 97
+44 (0) 7446 87 37 97